Shape problem 8 / Solution
![[Diagram]](diagrams/29/4962623cf89f07f89b123435e3d96e17.png)
Why are the other moves wrong?
The correct solution is a good example of avoiding giving your opponents forcing moves (kikashi). In the following diagrams, I have tried to explain why the alternatives are not good.
![[Diagram]](diagrams/9/8af73953504c533a71f7bed8e473fecc.png)
If Black answers at 2, he gives White a free forcing move at 3. Compare this with the correct solution (tewari). If White played 3 in the correct solution, would Black play 2? Maybe, but she keeps the option of playing elsewhere and there are probably bigger moves on the board...
![[Diagram]](diagrams/41/82734985b08b59f29c7c9cb0c0202dad.png)
If Black plays 2, White could play a (threatening to cut) or b and Black would still have to come back and play at the marked point. A white stone at a of course means that the black corner is even more open than before.
![[Diagram]](diagrams/10/9a82cfbe94204d970bbede14bbf755ae.png)
Grauniad: Could one say that move 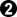 in the first diagram is a[n] honte move, or one of Kageyama's "proper" moves?
in the first diagram is a[n] honte move, or one of Kageyama's "proper" moves?
HolIgor: Neither. By a proper move Kageyama meant something slightly different. And by honte we mean a move that fixes a weakness while being a little bit slow. This is just a good shape, a move that leaves the opponent' weaknesses exposed while own shape solid.
Charles There is a Japanese term honsuji, or 'correct style'.
Grauniad: Just seen on rec.games.go: "[Go] takes a deep understanding of hard to define concepts just to be mediocre." :-(
Charles I believe the real importance of understanding correct style as a kind of theory of criticism of plays only kicks in at ama 5 dan - 6 dan. Or, to put it another and blunter way, you may think you're really closing the gap on the pros before then, but you might be wrong.
![[Welcome to Sensei's Library!]](images/stone-hello.png "Sensei's Library")